Unifying 3D Vision-Language Understanding via Promptable Queries
ECCV 2024
A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning.Tested across ten diverse 3D-VL datasets,
This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view im- ages) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training.
PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state- of-the-art on ScanNet200 by 4.9% (AP25), ScanRefer by 5.4% (acc@0.5), Multi3DRefer by 11.7% (F1@0.5), and Scan2Cap by 13.4% (CIDEr@0.5).Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input
Our main contributions are
 PQ3D Model
PQ3D Model
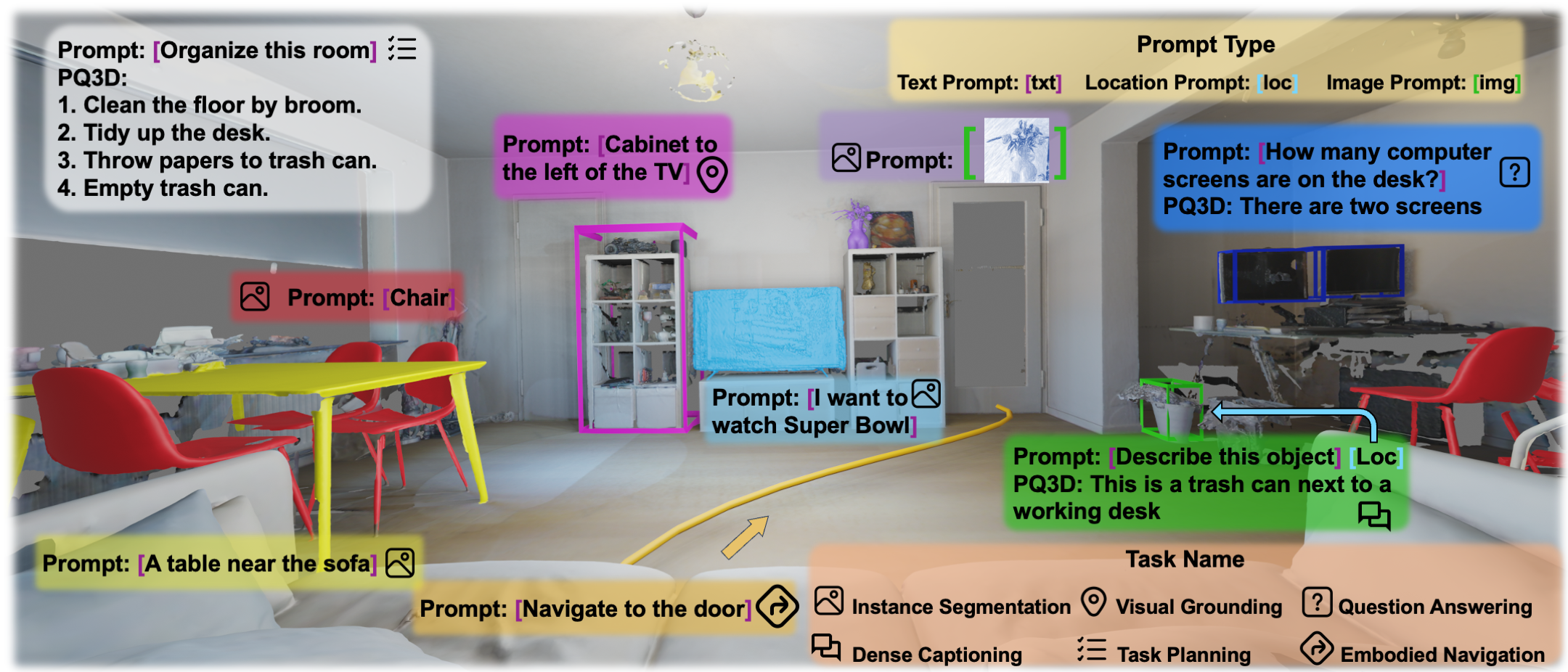
 Examples on 3D VL Understanding
Examples on 3D VL Understanding Qualitative results on promptable segmentation, visual grounding, question answering, dense captioning, object navigation, and task planning.

 Promptable Segmentation Results
Promptable Segmentation Results

@article{zhu2024unifying,
title={Unifying 3D Vision-Language Understanding via Promptable Queries},
author={Zhu, Ziyu and Zhang, Zhuofan and Ma, Xiaojian and Niu, Xuesong and Chen, Yixin and Jia, Baoxiong and Deng, Zhidong and Huang, Siyuan and Li, Qing},
journal={ECCV},
year={2024}
}